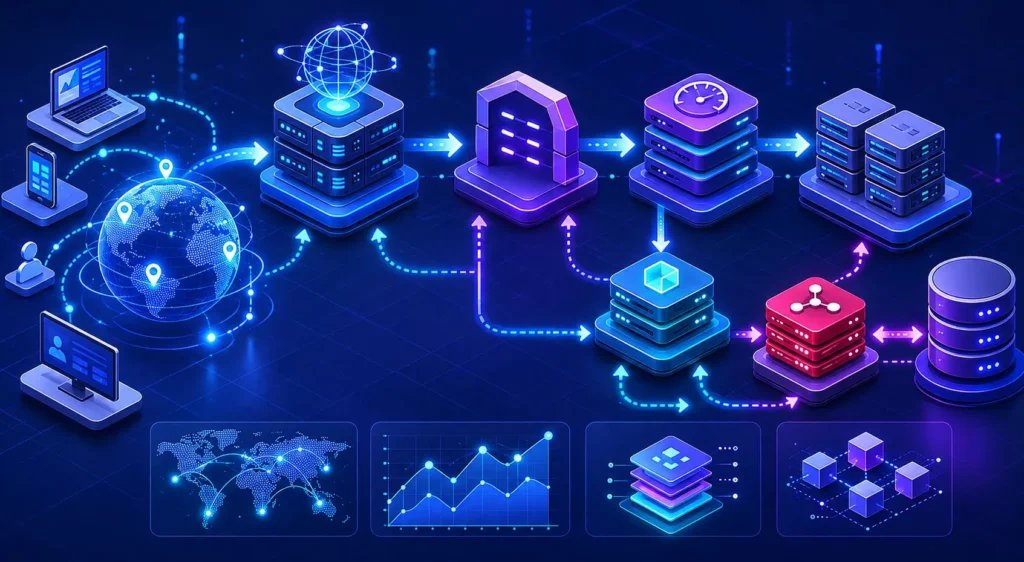
응답속도 문제는 대부분 “캐시를 쓰지 않아서” 발생하는 것이 아니다. 실제 운영 환경에서는 어떤 데이터를 어디에서 캐싱하고, 어떤 요청을 어느 계층에서 차단하느냐에 따라 성능 차이가 크게 달라진다. 특히 트래픽 규모가 커질수록 단일 Redis만으로는 한계가 드러난다. 그래서 대규모 서비스들은 CDN, API Cache, Local Cache, Distributed Cache를 계층적으로 조합하는 방향으로 구조를 설계한다.
실제 운영에서는 캐시 개수보다 어떤 요청을 앞단에서 제거할 수 있는지가 더 중요하다. 결국 캐시 아키텍처의 핵심은 “어떤 비용을 어느 레이어에서 줄일 것인가”를 결정하는 과정에 가깝다.
STEP 1. 응답속도가 느려지는 병목 위치부터 확인해야 한다
캐시 설계를 시작하기 전에 가장 먼저 해야 하는 일은 병목 위치를 찾는 작업이다. 많은 서비스가 응답속도가 느려지면 곧바로 Redis를 붙인다. 하지만 실제 운영에서는 DB보다 네트워크나 애플리케이션 CPU가 먼저 한계에 도달하는 경우도 많다.
예를 들어 API 응답 생성 과정에서 JSON 직렬화 비용이 크다면 Redis를 추가해도 CPU 사용량은 줄어들지 않는다. 반대로 읽기 요청 비율이 높은 서비스라면 캐시 효과가 매우 크게 나타난다.
그래서 운영 환경에서는 먼저 다음 항목을 관찰한다.
- DB Query Time
- Network Latency
- Application CPU Usage
- External API 호출 시간
- Cache Hit Ratio
- P95/P99 응답시간
특히 P95나 P99 응답시간이 중요한 이유는 평균 응답속도만으로 실제 사용자 경험을 판단하기 어렵기 때문이다. 순간적인 트래픽 증가나 특정 Hot Key 요청은 평균보다 Tail Latency에서 더 명확하게 드러난다.
캐시는 병목을 우회하거나 분산시키는 도구에 가깝고, 근본 원인을 해결하지 못하는 경우도 많다. 그래서 대규모 서비스일수록 캐시 적용 전에 관측 시스템부터 먼저 정비하는 경우가 많다.
실제로 캐시를 도입했는데도 응답속도가 더 느려지는 사례는 생각보다 자주 발생한다. Redis 호출 자체가 병목이 되거나 TTL 전략 문제로 DB 부하가 폭증하는 경우도 있다.
STEP 2. CDN 캐시는 가장 먼저 적용되는 레이어다
대규모 서비스에서 가장 먼저 부하를 줄이는 계층은 보통 CDN이다. 이미지, CSS, JavaScript 같은 정적 리소스 요청은 애플리케이션 서버까지 도달하지 않도록 설계하는 경우가 많다.
CDN의 가장 큰 장점은 원본 서버 요청 자체를 줄인다는 점이다. 사용자는 가까운 엣지 서버에서 콘텐츠를 받아오기 때문에 네트워크 지연도 감소한다.
특히 글로벌 트래픽이 많은 서비스에서는 CDN 효과가 매우 크다. 동일 이미지를 수백만 사용자가 반복 요청하는 상황에서 모든 요청을 원본 서버가 처리하는 구조는 비효율적이다.
실제로 글로벌 사용자가 증가한 이후 CDN Edge Cache를 적용하면서 해외 평균 응답속도가 크게 줄어드는 사례도 자주 발견된다. 미국과 유럽 사용자가 아시아 원본 서버까지 직접 접근하던 구조를 지역 Edge 서버가 대신 처리하면서 네트워크 지연 자체가 감소하는 것이다.
운영 환경에서는 다음과 같은 리소스를 우선 CDN으로 분리하는 경우가 많다.
- 이미지
- 동영상 썸네일
- JS/CSS 파일
- 다운로드 파일
- 공개 문서 페이지
최근에는 API 응답 일부까지 CDN에서 캐싱하는 구조도 많이 사용된다. 특히 실시간성이 높지 않은 공개 데이터는 CDN Edge Cache에서 처리하는 경우가 늘어나고 있다.
결국 CDN은 “애플리케이션 서버 이전 단계에서 트래픽을 차단하는 구조”라고 볼 수 있다.
STEP 3. API Gateway와 Application Cache를 분리해야 한다
캐시 구조를 단순하게 유지하려고 모든 캐싱을 애플리케이션 내부에서 처리하는 경우가 있다. 하지만 트래픽 규모가 커질수록 Gateway Cache와 Application Cache를 분리하는 편이 효율적이다.
API Gateway Cache는 요청 자체를 애플리케이션까지 전달하지 않는다. 즉, 인증이 필요 없는 공개 API나 자주 반복되는 응답은 Gateway 단계에서 바로 반환할 수 있다.
반면 사용자별 데이터는 다르다. 로그인 상태, 권한, 개인 설정이 포함된 요청은 단순 Gateway Cache로 처리하기 어렵다. 이런 데이터는 애플리케이션 내부 캐시나 Redis에서 관리하는 경우가 많다.
실제로 운영 환경에서는 Cache-Control 헤더 설정이 성능에 큰 영향을 준다. 동일 API라도 캐싱 가능 여부를 어떻게 정의하느냐에 따라 서버 부하 차이가 크게 발생한다.
| 캐시 레이어 | 주 역할 | 추천 사용 대상 |
|---|---|---|
| CDN Cache | 정적 콘텐츠 처리 | 이미지·JS·CSS |
| Gateway Cache | 반복 API 응답 처리 | 공개 API |
| Application Cache | 비즈니스 로직 캐싱 | 사용자별 데이터 |
| Redis Cache | 공유 데이터 저장 | 세션·랭킹·카운터 |
캐시를 계층화하는 이유는 단순하다. 비싼 요청일수록 앞단에서 최대한 제거하기 위해서다.
STEP 4. Local Cache와 Redis를 함께 사용하는 이유
트래픽이 증가할수록 모든 요청을 Redis로 보내는 구조는 한계가 생긴다. Redis는 빠른 저장소지만 결국 네트워크 기반 시스템이기 때문이다.
그래서 대규모 서비스에서는 Local Cache와 Distributed Cache를 함께 사용하는 경우가 많다. 자주 바뀌지 않는 데이터는 애플리케이션 메모리 안에 저장하고, 공유가 필요한 데이터만 Redis를 사용하는 방식이다.
예를 들어 다음 데이터는 Local Cache에 적합하다.
- 공통 설정값
- 국가 코드
- 카테고리 정보
- Feature Flag
- 자주 조회되는 메타데이터
반대로 실시간성이 중요하거나 여러 서버가 공유해야 하는 데이터는 Redis가 적합하다.
- 로그인 세션
- 실시간 재고
- 인기 랭킹
- 분산 락
- 실시간 카운터
운영 환경에서는 Local Cache 추가만으로 Redis 호출량이 크게 줄어드는 경우도 많다. 특히 네트워크 왕복 비용이 높은 구조에서는 효과가 더 크게 나타난다.
실제로 모든 요청이 Redis를 지나가던 구조에서 Local Cache를 추가한 뒤 Redis 네트워크 트래픽이 급감하는 사례도 자주 발견된다. 특히 공통 메타데이터처럼 자주 바뀌지 않는 데이터를 로컬 메모리에서 처리하면 응답속도 차이가 매우 크게 나타난다.
중요한 것은 “모든 데이터를 중앙 캐시에 저장하는 것”이 아니라 “어떤 데이터를 어느 계층에서 처리할 것인가”를 구분하는 작업이다.
STEP 5. Cache Aside 패턴이 가장 많이 사용되는 이유
실무에서 가장 많이 사용되는 캐시 패턴은 Cache Aside 방식이다. 애플리케이션이 먼저 캐시를 조회하고, 데이터가 없으면 DB에서 조회한 뒤 다시 캐시에 저장하는 구조다.
이 방식이 많이 사용되는 이유는 단순성과 운영 유연성 때문이다. 애플리케이션이 캐시 흐름을 직접 제어할 수 있기 때문에 특정 데이터만 선택적으로 캐싱하기 쉽다.
반면 Read Through 방식은 캐시 시스템이 직접 DB 조회를 담당한다. 구조는 단순해질 수 있지만 캐시 계층 의존성이 커진다.
Write Through 방식은 DB 저장과 동시에 캐시도 갱신한다. 데이터 일관성 유지에는 유리하지만 쓰기 비용이 증가한다.
실제 운영에서는 완벽한 정답 패턴보다 서비스 특성에 따라 조합하는 경우가 많다. 읽기 비율이 압도적으로 높은 서비스라면 Cache Aside가 가장 현실적인 선택이 되는 경우가 많다.
하지만 Cache Aside도 문제가 없는 것은 아니다. 캐시 삭제 시점이 꼬이면 오래된 데이터가 다시 저장될 수 있고, 캐시 미스가 동시에 발생하면 DB 부하가 급증할 수 있다.
특히 이벤트 오픈 직전에 Cache Warming 없이 서비스를 시작했다가 Redis와 DB 요청이 동시에 폭증하는 사례도 자주 발생한다. 그래서 운영 환경에서는 인기 데이터 일부를 미리 캐시에 적재하는 전략도 함께 사용한다.
운영 환경에서는 패턴 자체보다 “실패 시 어떤 문제가 발생하는가”를 더 중요하게 본다.
STEP 6. 트래픽 규모가 커질수록 Multi-layer Cache 구조가 필요하다
초기 서비스에서는 단일 Redis만으로도 충분한 경우가 많다. 하지만 트래픽 규모가 커질수록 중앙 캐시 하나에 모든 요청이 집중되기 시작한다.
특히 다음 상황에서는 단일 캐시 구조의 한계가 빠르게 나타난다.
- 인기 데이터 요청 집중
- 지역별 트래픽 증가
- API 호출량 급증
- 대규모 이벤트 트래픽
- 실시간 랭킹 요청 증가
이때 많이 사용하는 방식이 Multi-layer Cache 구조다. CDN, Local Cache, Redis, DB를 계층적으로 연결해 요청을 분산하는 방식이다.
예를 들어 이미지 요청은 CDN에서 처리하고, 공통 메타데이터는 Local Cache에서 처리하며, 공유 데이터만 Redis를 거치도록 구성할 수 있다.
Hot Key 문제를 줄이기 위해 Redis Cluster와 샤딩 전략을 함께 사용하는 경우도 많다. 특정 노드 하나에 요청이 몰리지 않도록 데이터를 여러 노드에 분산하는 방식이다.
| 구조 | 장점 | 단점 |
|---|---|---|
| 단일 Redis | 구조 단순 | 병목 집중 가능 |
| Redis Cluster | 확장성 우수 | 운영 복잡도 증가 |
| Multi-layer Cache | 부하 분산 효과 큼 | 설계 난이도 높음 |
실제 운영에서는 “Redis 서버 성능을 높이는 것”보다 “애초에 Redis까지 도달하는 요청 수를 줄이는 것”이 더 효과적인 경우도 많다.
대규모 서비스일수록 캐시 서버 성능보다 요청을 얼마나 여러 계층으로 분산했는가가 더 중요해진다.
STEP 7. 결국 중요한 건 캐시 개수가 아니라 비용 분산 구조다
많은 팀이 캐시 서버를 추가하면 성능이 해결될 것이라고 생각한다. 하지만 실제 운영에서는 비용 이동 구조를 먼저 본다.
DB 부하를 줄이는 대신 네트워크 비용이 증가할 수도 있다. 응답속도를 줄이는 대신 데이터 일관성 관리 비용이 커질 수도 있다. Local Cache를 추가하면 Redis 호출량은 줄어들지만 메모리 사용량은 증가한다.
결국 캐시 아키텍처는 속도 최적화만의 문제가 아니다. 네트워크, CPU, 메모리, 운영 복잡도, 데이터 정합성 사이에서 균형을 잡는 과정에 가깝다.
실제 운영 환경에서는 다음 기준으로 캐시 전략 우선순위를 정하는 경우가 많다.
- 읽기 요청 비율
- 데이터 변경 주기
- 네트워크 비용
- 글로벌 트래픽 규모
- 실시간성 요구 수준
- 장애 발생 시 영향 범위
그래서 대규모 서비스일수록 “캐시를 얼마나 많이 사용하는가”보다 “어떤 요청을 어느 계층에서 제거하는가”에 더 집중한다.
응답시간을 줄이는 핵심은 캐시 서버를 늘리는 것이 아니다. 가장 비싼 요청이 애플리케이션과 DB까지 도달하지 않도록 설계하는 것이다.



